
Cayendo por la madriguera del conejo
El tema de la inteligencia artificial (IA) es un pozo mucho más profundo que la madriguera por la que cae Alicia persiguiendo al conejo. Llevo muchos años estudiándolo a nivel teórico y también probando e incluso ayudando a desarrollar herramientas de legaltech basadas en IA y, a pesar de todo ello, hay multitud de cuestiones que se me escapan. Es frustrante pero también estimulante.
Este artículo es una recopilación de las notas que he ido tomando después de tener conversaciones con expertos a nivel técnico, leer muchos artículos y visualizar varios videos, con el objetivo de entender mejor lo que hay detrás del concepto de moda: la inteligencia artificial generativa (IAG).
Disclaimer 1: no esperéis una descripción técnicamente precisa y completa de los conceptos. He sacrificado rigor en aras a hacerlo más entendible.
Disclaimer 2: me ha apoyado en IAG para entender mejor y explicar algunos conceptos, en concreto en Bing con ChatGPT por detrás. Los textos en cursiva están tomados de las respuestas de Bing (debidamente supervisadas…)
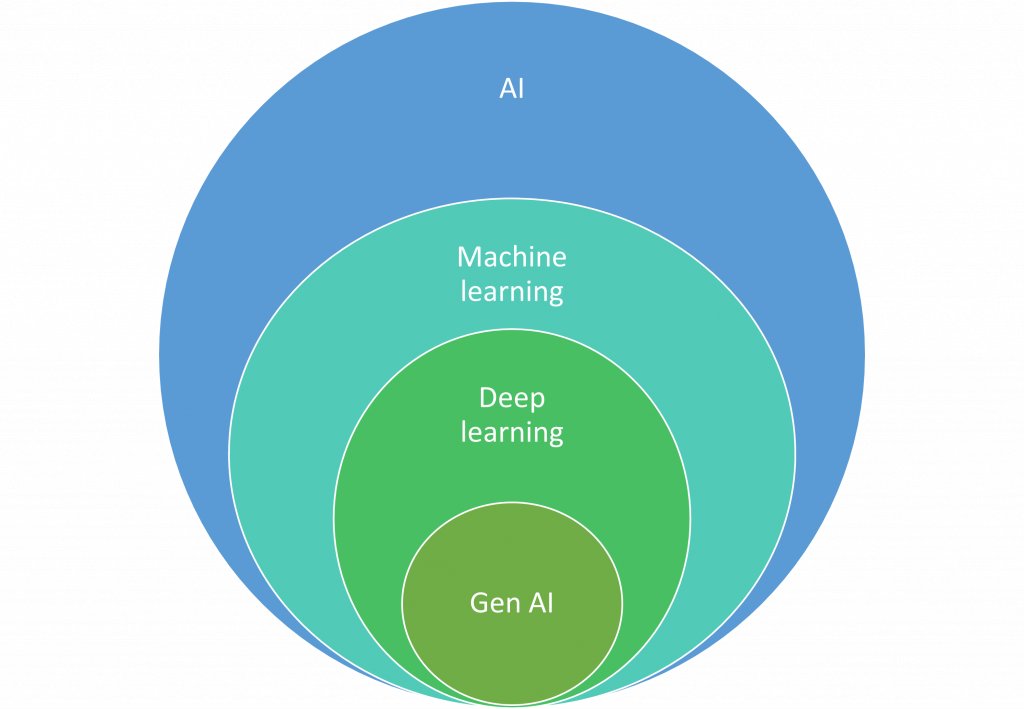
Después de esta pequeña introducción, arrancamos. La ilustración de arriba nos ayuda a ubicarnos y a empezar a distinguir conceptos. Empezando por el más amplio, lo primero que hay que señalar es que existen muchas definiciones de inteligencia artificial. Transcribo a continuación la de la última versión de las recomendaciones de la OCDE sobre el uso de la IA de noviembre de 2023: “un sistema de IA es un sistema basado en máquinas que, con objetivos explícitos o implícitos, infiere, a partir de la entrada que recibe, como generar salidas tales como predicciones, contenidos, recomendaciones o decisiones que pueden influir en entornos físicos o virtuales. Los distintos sistemas de IA varían en sus niveles de autonomía y capacidad de adaptación tras su despliegue.”
Una forma más simple de decirlo es que decir que llamamos inteligencia artificial a la capacidad de las máquinas de hacer cosas que consideramos humanas, por ejemplo, mantener una conversación. Otra de esas cualidades es aprender y aquí es donde entra en juego el concepto de aprendizaje automático (machine learning en inglés), que se empieza a desarrollar en los años 90 impulsado por el aumento en la capacidad de cómputo y la disponibilidad de un número cada vez más grande de datos.
El aprendizaje de la máquina se produce a través del análisis de información. Cuantos más datos procese, mejores predicciones podrá hacer. Los modelos de aprendizaje automático normalmente trabajan con datos estructurados. Si los datos no están tabulados, etiquetados u organizados de alguna forma, los modelos de aprendizaje automático no logran comprenderlos con precisión. Como explica Elen Irazabal en su libro La Inteligencia Artificial explicada para abogados, el aprendizaje automático puede estar supervisado por personas o no. En este último caso, la máquina descubre patrones en conjuntos de datos sin intervención humana y proporciona resultados precisos, como por ejemplo agrupar clientes según las características de sus compras. Por contra, el aprendizaje supervisado es útil para hacer predicciones a partir de datos anteriores: predecir el tiempo, calcular el precio de una casa, recomendar una película, clasificar correos electrónicos entre spam y no spam, clasificar imágenes de animales, etc.
Sin embargo, la mayor parte de información y datos disponibles no están estructurados. Añadido a lo anterior, el volumen ha crecido exponencialmente: la cantidad de datos digitales creados o replicados a nivel mundial se ha multiplicado por más de treinta en la última década, pasando de dos zetabytes en 2010 a 64 en 2020. Para 2025 se espera que esa cifra supere los 180 zetabytes en 2025, lo que supondría un crecimiento medio anual de casi el 40% en cinco años.
En ese contexto es donde el aprendizaje profundo es más eficaz que el aprendizaje automático y permite resolver problemas más complejos. El aprendizaje profundo (deep learning en inglés) utiliza algo llamado “redes neuronales” para aprender de los datos. Estas redes neuronales tienen diferentes capas de aprendizaje, y cada capa aprende diferentes características de los datos. Por ejemplo, en el caso de una red neuronal diseñada para reconocer imágenes, la primera capa podría aprender a reconocer bordes, la siguiente podría aprender a reconocer formas básicas, y así sucesivamente, hasta que las capas finales aprenden a reconocer objetos completos.
El Deep Learning es una forma de IA que aprende de los datos de la misma manera que un humano lo haría: empezando por los conceptos básicos y construyendo una comprensión más profunda a medida que se expone a más y más datos.
Cito de nuevo a Elen Irazabal, que nos explica que cuando se entrena una red neuronal, todos sus pesos y umbrales se fijan inicialmente en valores aleatorios. Los datos de entrenamiento se introducen en la capa inferior (la capa de entrada) y pasan por las capas sucesivas, multiplicándose y sumándose de forma compleja, hasta que finalmente llegan, radicalmente transformados, a la capa de salida. Durante el entrenamiento, los pesos y los umbrales se ajustan continuamente hasta que los datos de entrenamiento con las mismas etiquetas producen sistemáticamente resultados similares. Para que nos hagamos una idea de la dificultad, las redes neuronales más sofisticadas constan de miles de millones de valores o parámetros.
La inteligencia artificial generativa es una aplicación del aprendizaje profundo que utiliza redes neuronales para crear nuevo contenido (texto, audio, fotos o video), por ejemplo ChatGPT, Llama, Bard, Stable Diffusion o Dall E. En adelante nos vamos a centrar en las IAGs de texto, que son aquellas capaces de generar frases y párrafos sintáctica y gramaticalmente correctos, a base de predecir la siguiente palabra.
¿Cómo hacen lo que parece magia? Para explicarlo bien, tenemos que introducir algunos términos técnicos, empezando por Large Language Models (LLMs) o modelos de lenguaje de gran tamaño. Los LLMs son los modelos de aprendizaje profundo que usan las IAGs. Se entrenan con enormes cantidades de datos de texto disponible en internet, a partir de los cuales infieren patrones y reglas. Una vez entrenados, los LLMs se pueden adaptar fácilmente para realizar múltiples tareas mediante conjuntos relativamente pequeños de datos supervisados, un proceso que se conoce como ajuste fino.
Los LLMs se basan en Transformers. Los Transformers surgen de un paper de Google de 2017 llamado “Attention is All You Need” y son un tipo de arquitectura de red neuronal que se utiliza en el procesamiento del lenguaje natural. A diferencia de otros modelos que procesan las palabras una por una en orden (como si estuvieran leyendo), los Transformers pueden procesar todas las palabras de una secuencia al mismo tiempo (como si estuvieran viendo una imagen), lo que les permite entender el contexto y las relaciones entre las palabras de manera más eficiente. Hasta la aparición de los transformers, las redes neuronales que se aplicaban al procesamiento de lenguaje natural no ofrecían un rendimiento óptimo porque no eran capaces de captar bien la relación entre las palabras de una misma frase o párrafo, ni de prestar más atención a las palabras más relevantes dentro de ese contexto.
Hemos dicho palabras y realmente lo que procesan los modelos de lenguaje son tokens o secuencias de caracteres que se encuentran en un conjunto de texto. Pueden ser palabras o trozos de palabras. Debajo podéis ver un ejemplo. 19 palabras equivalen a 24 tokens. En este enlace se pueden hacer más pruebas.

Recientemente se ha anunciado que GPT-4 va a procesar 128.000 tokens. Esto significa que GPT-4 puede manejar una cantidad de texto mucho mayor en comparación con las versiones anteriores, que tenían un límite de 4.000 a 16.000 tokens. Para ponerlo en perspectiva, 128.000 tokens son aproximadamente equivalentes a 300 páginas de texto. Esto permite que el modelo procese y genere respuestas para textos mucho más largos, como documentos técnicos completos o libros enteros.
Este es relevante porque el limite de tokens afecta tanto al input o prompting como al output o respuesta de la IAG. Cuanto más contexto, mayor precisión.
El concepto de token está muy relacionado con el de embedding, que es una representación numérica (o vector) de un token. Estos vectores capturan el significado y el contexto de los tokens. Por ejemplo, palabras similares tendrán embeddings similares. Esto permite a las máquinas entender las relaciones y similitudes entre palabras. Por lo tanto, en el procesamiento del lenguaje natural, los tokens se convierten en embeddings para que las máquinas puedan procesar y entender el texto.
Como explica José Luis Calvo en este hilo de Twitter, gracias a los embeddings se crea un espacio multidimensional en el que parece que se colocan algo cercano a los conceptos que están detrás de las palabras. La relación que se crea entre “rey” y “reina” es la misma que entre “hombre” y “mujer” o entre “king” y “queen”. Ese vector tiene información semántica sobre el término utilizado. Como el modelo conceptual es extremadamente grande, tanto en conceptos como en dimensiones, podríamos afirmar que se crea una especie de versión simplificada de un modelo conceptual del mundo.
Para poder llevar a cabo todo lo anterior, hace falta una capacidad de cómputo superlativa y aquí es donde entran en juego las Unidades de Procesamiento Gráfico (GPUs por sus siglas en inglés), que son tarjetas gráficas compuestas por miles de núcleos que trabajan juntos y que están diseñadas especialmente para acelerar el procesamiento de datos para la IA, como por ejemplo las que comercializa Nvidia. Las GPUs son una herramienta esencial en el aprendizaje profundo debido a la posibilidad que ofrecen de realizar cálculos en paralelo, su eficiencia superior a las CPUs para ciertos tipos de cálculos y su capacidad para acelerar el entrenamiento de los modelos.
Hablábamos antes de los parámetros y eso me lleva al último concepto que quería introducir, que es el de temperatura. Cuando inicias una nueva conversación en el chat de Bing, te da a elegir el estilo de conversación: más creativo, más equilibrado o más preciso. De esta forma, la herramienta te deja decidir y ajustar mínimamente los parámetros y la forma en que te va a contestar. Si eliges mayor precisión, reproducirá más fielmente la información que ha utilizado para su entrenamiento. Si escoges mayor creatividad, ofrecerá un planteamiento más innovador y abierto aunque es posible que alucine y se invente total o parcialmente la respuesta.
Quiero acabar con un video largo pero que merece mucho la pena. Es una entrevista con Nico Metallo, de Amazon, en el que explica de forma muy didáctica multitud de conceptos relacionados con la inteligencia artificial. Os lo recomiendo aunque aviso que dura más que una película…